
1 Einleitung
In vielen Unternehmen ist die klassische, häufig batch-basierte Bereitstellung von Daten nicht mehr ausreichend und es wird nach Möglichkeiten gesucht, eine real-time-nahe und event-basierte Datenversorgung bereitzustellen. Ein Mittel hierfür kann ein sog. Change Data Capture (CDC) Tool in Kombination mit einer Streaming Plattform wie Apache Kafka darstellen. Ein CDC-Tool ist im Gegensatz zu einem ETL-Tool deutlich ressourcen-schonender. Beide Tools bilden jedoch nur die technischen Events ab. Business Events als auch Domain Driven Design gehen hierbei noch einen Schritt weiter.
Während CDC-Tools aus der klassischen Anwendung entstanden sind, Daten kosteneffizient und performant von einer Datenbanktabelle zu einer anderen zu replizieren, sind die Möglichkeiten für die Zielseite über klassische Datenbanken hinausgewachsen. So sind Zielsysteme wie Apache Hadoop, Apache Kafka, IBM MQ, etc. im Bereich der Streaming- und Queuing-Lösungen hinzugekommen. Cloud-basierte Streaming-Systeme wie Azure Event Hub als auch Datenbanksysteme wie Amazon RDS, Snowflake (AWS, GCP, Azure), Microsoft Azure Database, Google Cloud SQL, etc. sind ebenfalls hinzugekommen. Damit eröffnen sich für Unternehmen diverse Möglichkeiten, Daten aus existierenden on-premise Systemen mit der Cloud zu verbinden sowie real-time-nahe Events derselbigen in die Cloud zu replizieren. Immer mehr CDC-Toolanbieter haben diese Möglichkeiten erkannt und bieten einen Support für diese Zielsysteme an. Neben kommerziellen CDC-Tools von bekannten Herstellern wie IBM InfoSphere Data Replication, Oracle Golden Gate, Qlik Replicate, Informatica PowerExchange, Talend, etc. gibt es ebenfalls frei verfügbare CDC-Tools wie bspw. Debezium, StreamSets, etc., wobei bei diesen eine Lizenz vom Datenbankprovider erforderlich sein kann.
Apache Kafka hat in den vergangenen Jahren immer weiter an Popularität zugenommen und wird aktiv von der Confluent Inc. weiterentwickelt. Neben der Kafka Streaming Plattform selbst werden vor allem Kafka Konnektoren weiterentwickelt, die sich ebenfalls zu diversen Quell- und Zielsystemen verbinden können. So gibt es für einige Datenbanken beispielsweise bereits Debezium Quellkonnektoren, die (zu Teilen) die Aufgabe eines CDC-Tools erledigen können. Weiterhin entwickelt und vertreibt Confluent eine eigene kommerzielle Kafka-Version mit zusätzlichen Features, die sog. «Confluent Platform», die entweder on-premise, auf einer der bekannten Cloud-Plattformen (AWS, GCP, etc.) oder auf der «Confluent Cloud» installiert und genutzt werden kann. Neben Kafka Connect gibt es zudem noch Kafka Streams und ksqlDB für die Entwicklung von Streaming Applikationen. In der nachfolgenden Abbildung 1 ist die Kombination eines CDC-Tools mit dem Kafka Ökosystem dargestellt.

2 Change Data Capture (CDC)
2.1 Definition
Der Ausdruck Change Data Capture (CDC) wird vor allem im Datenbankumfeld verwendet und bezeichnet die technischen Möglichkeiten um Änderungen, häufig auch «Deltas» genannt, aus der Quelldatenbank zu identifizieren und diese zu verwenden bzw. weiterzuverarbeiten.
2.2 Arten von CDC
Bei CDC kann unterschieden werden zwischen Procedures, Triggers, Query-based und Log-based CDC. Alles sind technische Methoden und Ansätze um eine Quelländerung als Event zu erkennen und weiterzugeben.
2.3 Historischer Rückblick: Prozeduren und Trigger
In der Vergangenheit war die Verwendung von Datenbank Prozeduren oder Triggern ein gängiges Mittel, um Quelländerungen zu erkennen und abzugreifen. Prozeduren, sog. Stored Procedures, im CDC-Kontext werden von der jeweiligen Quellapplikation aufgerufen, um DML-Operationen auf der Zieltabelle durchzuführen. Trigger greifen im Vergleich zu Prozeduren die Änderung erst von der jeweiligen Quelltabelle ab, d.h. wenn die DML-Operationen bereits gegen die Datenbank und Quelltabelle abgesetzt wurden. Trigger sind somit aktive „Listener“ auf einer Tabelle. Zusätzlich können neben den DML-Operationen programmatisch weitere Aktionen auf der Datenbank ausgeführt werden, beispielsweise eine eigene Protokolltabelle über die Änderung zu führen (sog. Log Trigger), bei einer Änderung weitere Tabellen zu befüllen oder direkt eine nachgelagerte komplexere Verarbeitung gegebenenfalls mit einer Businesslogik abhängig von der jeweiligen Änderung durchzuführen. Auf Datenbankänderungen können Trigger analog zu Prozeduren programmatisch reagieren oder sogar eine Prozedur aus einem Trigger heraus aufrufen.
Im Folgenden sind einige Gründe dafür aufgelistet, dass Prozeduren und Trigger heute für CDC selten im Einsatz sind:
• Je nach Datenbank sind sie in einer datenbanknahen Programmiersprache wie PL/SQL, SQL PL, Transact SQL, etc. geschrieben, wodurch sie stark mit der jeweiligen Datenbank verknüpft sind und es entsprechende Entwickler benötigt
• Trigger sind ressourcenintensiv, da sie einen aktiven Prozess pro Tabelle darstellen
• Prozeduren können ressourcenintensiv sein, je nach implementierter Logik and Anzahl
• Je nach Design kann die Skalierbarkeit problematisch sein, abhängig davon wie viele Systeme die Änderungen wie erhalten
• Bei datenbanknahen Programmiersprachen ist es häufig nicht möglich Events an eine Streaming Plattform wie Kafka zu senden (Ausnahmen sind bspw. Java-basierte APIs)
2.4 Query-based CDC
Der Query-based CDC-Ansatz beschreibt das Ausführen von SQL-Queries gegen die Quelldatenbank, um Änderungen an den relevanten Tabellen zu ermitteln. Hierfür ist es erforderlich, dass die entsprechenden Tabellen ein Attribut zur Delta-Ermittlung enthalten. Dies kann beispielweise ein Attribut mit einem Timestamp, einer Versionsnummer oder einem Statusfeld sein. Hierbei kann die Wahl des CDC-Attributes auf Quellseite implizit dazu führen eine entsprechende Logik bei der Implementierung von DML-Operationen anzuwenden.
based CDC-Ansatz beschreibt das Ausführen von SQL-Queries gegen die Quelldatenbank, um Änderungen an den relevanten Tabellen zu ermitteln. Hierfür ist es erforderlich, dass die entsprechenden Tabellen ein Attribut zur Delta-Ermittlung enthalten. Dies kann beispielweise ein Attribut mit einem Timestamp, einer Versionsnummer oder einem Statusfeld sein. Hierbei kann die Wahl des CDC-Attributes auf Quellseite implizit dazu führen eine entsprechende Logik bei der Implementierung von DML-Operationen anzuwenden.
Der Query-based CDC-Ansatz kann darüber hinaus keine Löschungen in der Quelltabelle erkennen, da diese Events nur durch einen Vollbestandsabgleich identifiziert werden können.
2.5 Log-based CDC
Der Log-based CDC-Ansatz ist der bekannteste und am häufigsten referenzierte Ansatz, wenn von Change Data Capture bzw. CDC die Rede ist. Vor allem wird dieser Ansatz dann referenziert, wenn es um CDC-Tools geht.
Dieser Ansatz beschreibt das Erkennen von Datenbankänderungen durch das Auslesen der Datenbanklogfiles. Dabei können neben DML-Änderungen auch DDL-Änderungen erkannt werden. Für diesen Ansatz ist es i.d.R. notwendig, dass die Datenbank mehr loggt als standardmäßig eingestellt ist und dass für einzelne Tabellen, die anzubinden sind, ebenfalls weitere Konfigurationen durchgeführt werden müssen. Das intensivere Logging führt entsprechend zu einer höheren Ressourcenbeanspruchung auf Datenbankseite, wobei hier vor allem der für die Logs notwendige Speicherplatz gemeint ist.
Im Folgenden findet sich eine Übersicht der Vor- und Nachteile dieses Ansatzes:

Ein wesentlicher Aspekt bei dem Log-based CDC-Ansatz ist, dass ein CDC-Tool benötigt wird, um die üblicherweise proprietären Datenbanklogs auszulesen und zu verarbeiten. Je nach Quelldatenbank und Auswahl des CDC-Tools sind hierfür (in der Regel) entweder zusätzliche Lizenzen beim Datenbankanbieter oder beim CDC-Toolanbieter zu erwerben. Neben den kommerziellen CDC-Tools wie Qlik Replicate, IBM InfoSphere Data Replication, Informatica PowerExchange, etc. gibt es einige kostenfreie, teilweise open-source basierte Anbieter wie Debezium, StreamSets, etc. Hier sollten die unterstützten Quelldatenbanken und Zielsysteme beachtet werden.
Ein wesentliches Qualitätsmerkmal eines CDC-Tools ist die Durchführung eines Initial Loads mit anschließender lückenloser Delta-Verarbeitung. Da es aus dem Datenbanklog i.d.R. nicht möglich ist einen Initial Load durchzuführen, bringen hier die CDC-Tools meist eine Initial Load Funktionalität (per SQL Full Table Scan) mit und sorgen für die Konsistenz zwischen Initial Load und Delta (CDC) Daten.
Weiterhin werden diverse Zielsysteme, unter anderem Cloud-basierte und vor allem Streaming / Event Plattformen wie bspw. Apache Kafka, ebenfalls unterstützt.
In der folgenden Abbildung 2 wird der CDC-Informationsfluss veranschaulicht.

3 Apache Kafka
3.1 Architektur
Apache Kafka, welches primär von der Confluent Inc. weiterentwickelt wird, stellt eine logbasierte Streaming Lösung dar.
Die Kafka Architektur ist in Abbildung 3 dargestellt. Diese umfasst die folgenden Elemente:
· Producer: Sender von Nachrichten/Records nach Kafka unter Benutzung der Producer-API.
· Consumer: Empfänger/Konsument von Nachrichten aus Kafka Topics mit Hilfe der Consumer-API.
· Zookeeper: Enthält Kafka Cluster Informationen über Broker, Topics, Partitionen, etc.
· Broker: Kafka Nodes, welche den Logstream und damit die Nachrichten enthalten.
Wesentliche Vorteile von Kafka sind hierbei:
· Near-Realtime Verarbeitung
· Hoher Datendurchsatz durch verteilte Verarbeitung
· Entkopplung von Quell- und Zielsystemen (Asynchronität)
· Ein Producer – viele Consumer

Innerhalb eines Brokers werden Nachrichten (Records) in Topics gespeichert, die aus sog. Partitionen, welche wiederum aus sog. Segmenten bestehen. Dabei werden verschiedene Partitionen auf verschiedenen Brokern gespeichert bzw. redundant repliziert. In Abbildung 4 ist die Beziehung zwischen Topics, Partitionen und Segmenten abgebildet.
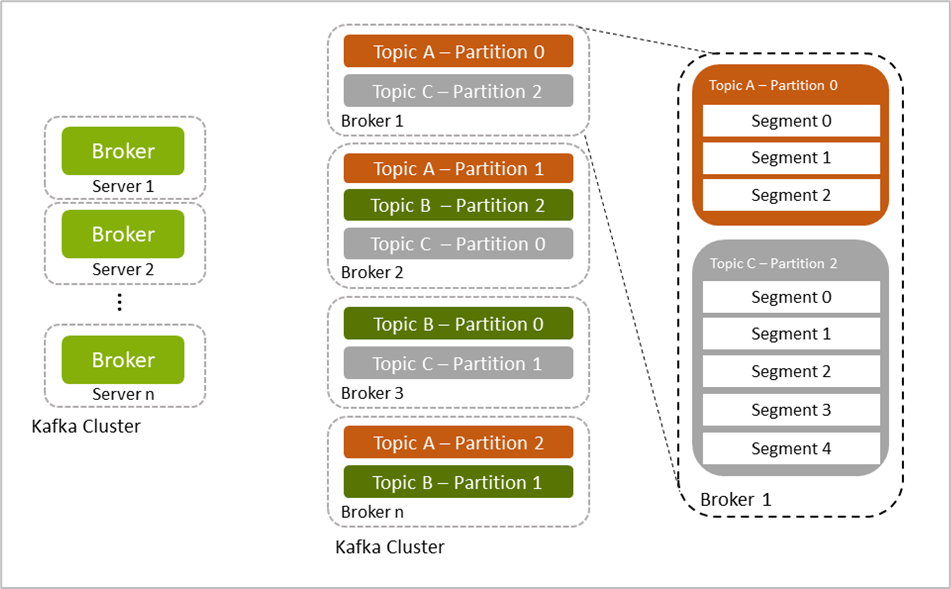
Für die Verteilung auf Partitionen wird ein sog. Partitioner verwendet. Neben dem Default-Partitioner ist es möglich andere use-case bezogene Partitioner selbst zu implementieren und zu verwenden.
3.2 Kafka Connect als Query-based CDC
Neben der Möglichkeit mit einem eigenen Kafka Producer oder Consumer eigene Daten direkt nach Kafka zu schreiben, stellt Kafka Connect mit sog. Connect Nodes weitere standardisierte Möglichkeiten der Datenanbindung bereit. Mit Kafka Connect ist es möglich die Datenanbindung diverser Quell- und Zielsysteme durch die Konfiguration des entsprechenden Connectors leicht anzubinden.
4 CDC-Tools in Kombination mit Apache Kafka
4.1 Verschlüsselung
Häufig wird Kafka auf einer der Cloud Plattformen (Azure, GCP, AWS) betrieben. Dabei werden teilweise Daten aus on-premise Bestandssystemen in die Cloud nach Kafka übertragen. Hierfür ist es empfehlens¬wert diese Verbindung zu verschlüsseln. Weiterhin ist ratsam die Verbindung zwischen Applikationen, die bereits in der Cloud laufen, und Kafka zu verschlüsseln. Hierfür gibt es diverse Verschlüsselungspro¬tokolle wie SSL/TLS, mTLS, SASL_SSL . Dies gilt im Übrigen ebenfalls für die ggf. vorhandene Schema Registry.
4.2 Nachrichtenformat: AVRO, Protobuf oder JSON
Bei der Einrichtung von Kafka ist es möglich ein Nachrichtenformat (im Folgenden Schema genannt) wie AVRO, Protobuf oder JSON zu den Inputnachrichten mitzu¬geben. Ein explizites Schema erfordert ein zusätzliches Aufsetzen einer Schema Registry. Es ermöglicht weiterhin eine Validierung von Schema-Änderungen („Schema Compatibility“). Ob ein Schema verwendet wird, kann von Topic zu Topic variieren. Häufig ist es bei CDC-Tools jedoch so, dass diese etwas weniger flexibel sind und nur eine Einstellung des Schemas pro Verbindung / Endpoint möglich ist. Gleichwohl können mehrere Verbindungen / Endpoints eingerichtet werden, sodass alle (vom CDC-Tool) unterstütz¬ten Schemata mit einem CDC-Tool abgedeckt werden können.
4.3 Partitionierung
Die Partitionierung sorgt zum einen für die Verteilung der Daten auf dem Kafka Cluster und damit auch für die Möglichkeit der Parallelisierung. Zum anderen führt die Verwendung von mehr als einer Partition in der Regel dazu, dass die Änderungsreihenfolge nicht eingehalten werden kann. Die Reihenfolge spielt bei CRUD-Operationen, vor allem Insert, Update und Delete, eine wesentliche Rolle. Abhängig vom CDC-Tool kann die Reihenfolge im Post-Processing jedoch auf Basis von CDC-Metadaten ermittelt und wiederhergestellt werden.
4.4 Komprimierung
Abhängig davon wie viele Daten für welchen Zeitraum und mit welchem Replizierungsfaktor nach Kafka geschrieben werden, kann es sinnvoll sein, diese Daten zu komprimieren. Komprimierung kann entweder im Producer oder auf Kafka Cluster Seite durchgeführt werden. Dabei ist es möglich bis zu 80% des Datenvolumens einzusparen. Komprimierungsmethoden sind u.a. Gzip, Snappy, Lz4, Zstd . Je nach CDC-Tool werden nicht alle Komprimierungsmethoden unterstützt. Die Komprimierungsmethode ist zudem ein Trade-Off zwischen Komprimierungsfaktor und ‑geschwindigkeit. Um vor allem Netzwerk-Traffic einzusparen, empfiehlt es sich die Komprimierung auf Producerseite vor dem Senden durchzuführen. Zudem sollte beachtet werden, dass dann die Daten in den entsprechenden Kafka Topics nur komprimiert vorhanden sind und jeder Consumer diese erst dekomprimieren muss, bevor sie verarbeitet werden können, was wiederum CPU-Zeit (Compute Time) erfordert. Eine mögliche Alternative oder Ergänzung zur Komprimierung wäre die Verwendung von sog. Tiered Storage .
4.5 Auditing
Typischerweise sind CDC-Tools in der Lage sog. Before und After Images in einem Änderungsevent mitzuliefern. Diese Abbildungen enthalten die Werte vor einer Änderung und nach einer Änderung. Dadurch ist es möglich eine Auditfähigkeit einzuführen. Diese Funktionalität ist abhängig vom CDC-Tool. Wenn auditfähige Nachrichten erzeugt werden, so werden die enthaltenen Attribute doppelt vorkommen, häufig mit Präfixen unterschieden. Auditfähige Nachrichten verhindern jedoch das Produzieren und Erhalten von Kafka Delete Events, sog. Tombstone Events. Dies kann zu Problemen mit der DSGVO / GDPR Konformität führen.
4.6 Beispiele
4.6.1 Beispiel 1: Qlik Replicate
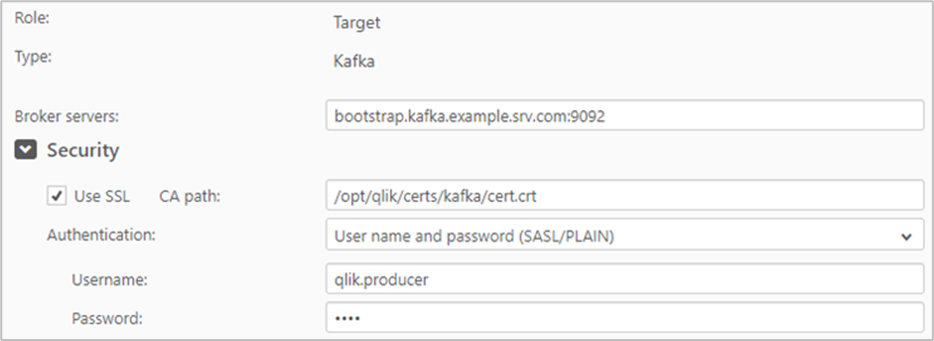
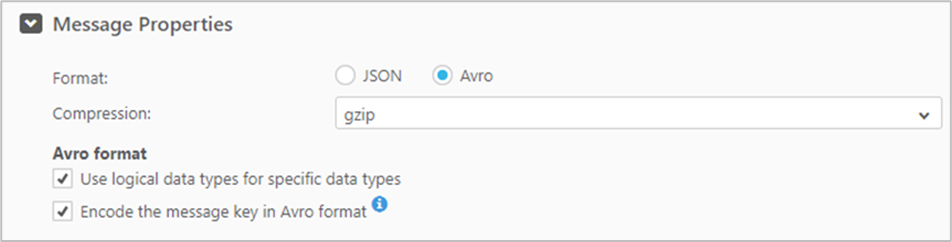
Qlik Replicate unterstützt bislang kein Protobuf.

4.6.2 Beispiel 2: IBM InfoSphere Data Replication
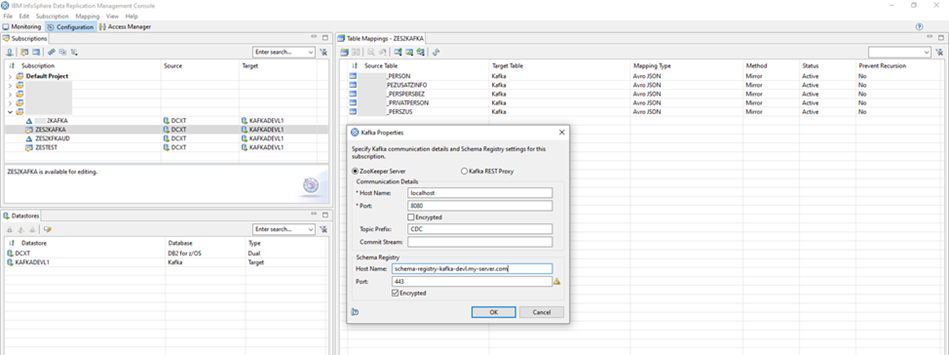
5 Vor- und Nachteile
Bei der Abwägung, inwieweit ein CDC-Tool in Kombination mit Kafka sinnvoll ist, gibt es diverse Vor- und Nachteile. Im Folgenden werden die wesentlichen aufgelistet.
Vorteile:
• Einfache und schnelle Art und Weise technische Events aus den Quellsystemen zu beziehen
• Transaktionssicher (verlustfrei)
• Lückenloser Übergang von Initial Load zu Delta Replikation
• Unterstützung der gängigsten Datenbanken als Quelle
• Unterstützung der gängigsten Kafka Funktionalitäten
• Zusätzliche Funktionalitäten (Filterung, Transformationen, Encoding, etc.)
• Tools sind leicht zu bedienen (und bieten i.d.R. eine GUI)
• Tools skalieren i.d.R. sehr gut
• DDL-Änderungen lassen sich erkennen
• Einsatz von CDC-Technologie entlastet die Quelldatenbank
• Ermöglicht reale Auditfähigkeit (technische und organisatorische Rahmenbedingungen vorausgesetzt)
Nachteile:
• Keine Abbildung von Business Events
• I.d.R. wiederkehrende Lizenzkosten (sofern CDC-Tool kommerziell)
• Lizenzkosten abhängig von den angebundenen Quell- und Zielsystemtypen
• Einmaliger Aufwand für Produkteinführung (Umgebungsaufbau, Installation, Konfiguration, etc.)
• Permanente Wartungs- und Weiterentwicklungskosten durch Einführung eines neuen Produktes
• Ggf. Vendor Lock-In
• I.d.R. nicht Highly Available (HA) Architektur
• Entstehung suboptimaler Architektur durch CDC-Tool-Funktionalitäten möglich (z.B. Lookups)
• Erfasst keine Batchoperationen (z.B. LOAD/UNLOAD, Truncate)
• Skalierung i.d.R. nur vertikal möglich
Bei der Evaluation eines Open-Source CDC-Tools wie Debezium oder anderen müssen die Aufwände (wie bei jedem kostenlosen Open Source Tool) für den fehlenden oder eingeschränkten Support und den aufwendigeren Betrieb sowie die Weiterentwicklung mitbetrachtet werden.
Nicht alle Vor- und Nachteile treffen bei jedem CDC-Tool zu, daher sind die o.g. Vor- und Nachteile potenziell möglich, aber nicht bei jedem CDC-Tool zutreffend.
6 Fazit
CDC-Tools bieten in Kombination mit Kafka eine sehr leistungsfähige Möglichkeit technische Events der Quellsysteme abzugreifen, jedoch ersetzen sie keine Business Events. CDC-Tools werden nach wie vor von zahlreichen Unternehmen eingesetzt und verlieren nicht an Beliebtheit. Sie bieten einen guten Einstieg in die Near-Realtime Verarbeitung. Um bei einer E2E-Betrachtung nicht in der Mitte „steckenzubleiben“ und auf eine Batch-Verarbeitung zurückzufallen, bietet Kafka eine ideale Möglichkeit für die Weiterarbeitung in Near-Realtime als auch wieder im Batch Modus (durch das Zurückschreiben in eine Datenbank). Zudem wird Kafka von allen gängigen CDC-Tools unterstützt, sowie auch Varianten von Kafka wie bspw. Azure Event Hub werden häufig ebenfalls unterstützt. Bei der Einführung eines CDC-Tools darf der monetäre und (wenn auch geringe) betriebliche Aufwand nicht unterschätzt werden, da es sich um ein eigenständiges Software Produkt handelt. Dies gilt ebenfalls für die Einführung von Kafka, wobei hierbei der Aufwand für Einführung und Betrieb i.d.R. deutlich höher ausfällt und ein Plattform-Team zu empfehlen ist. Beim CDC-Tool ist das in der Regel nicht der Fall. Alles in allem funktionieren CDC-Tools in Kombination mit Apache Kafka heutzutage sehr gut und ermöglichen Unternehmen den Einstieg in die realtime-nahe und eventbasierte Datenverarbeitung.
Erfahren Sie hier mehr über Lösungen im Bereich Data Management oder besuchen Sie eines unserer kostenlosen Webinare.




















